
Le but de cette article est d’analyser des données grâce à différents modèles de Machine Learning qui auront pour but de trouver des points d’amélioration mais aussi de proposer à l’utilisateur certaines fonctionnalités.
Pour analyser les données, nous allons travailler avec le logiciel Orange Data Mining qui nous permet d’importer un ou plusieurs jeux de données, qu’on peut également modifier comme l’on veut et enfin utiliser certains widgets qui vont effectuer des analyses et des algorithmes d’intelligence artificielle pour ensuite déterminer des prédictions sur des données choisies en amont.
Avant de commencer, nous allons dans un premier temps récupérer un jeu de données sur la liste des parkings en France fourni par L’Open data du gouvernement.
Première étape : Importation du fichier d’export dans Orange
Il est important avant de commencer de mettre en qualité le jeu de données, nous avons remarqué dans le fichier de départ, qu’il y avait des problèmes d’encodage, des problèmes de type de données
Pour cela, nous vérifions donc dans Orange que le fichier est qualitatif en passant par chaque attribut
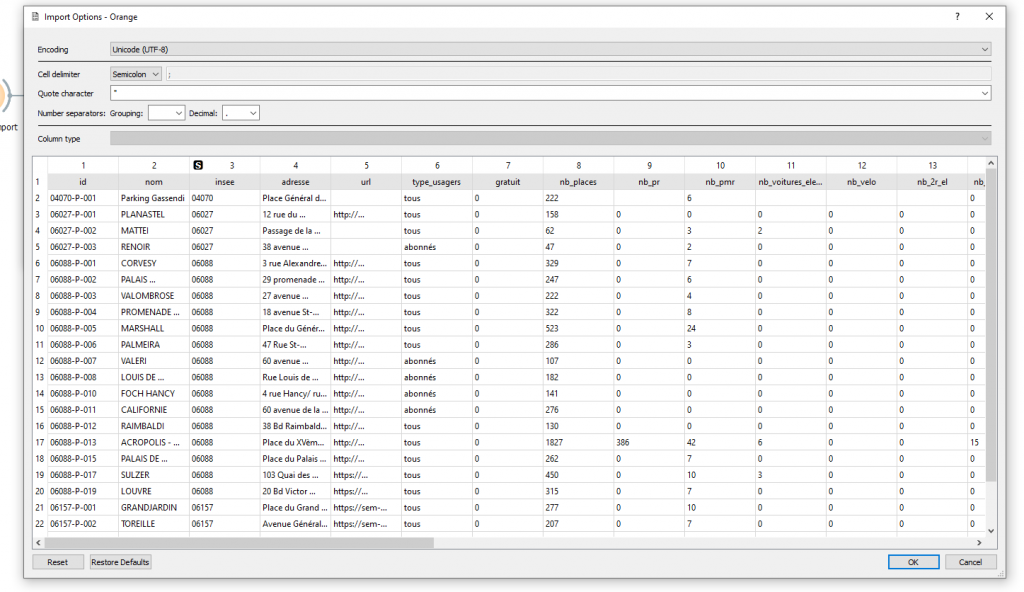
On remarque que le fichier est bien encodé et les chiffres et décimaux sont bien interprétés par Orange.
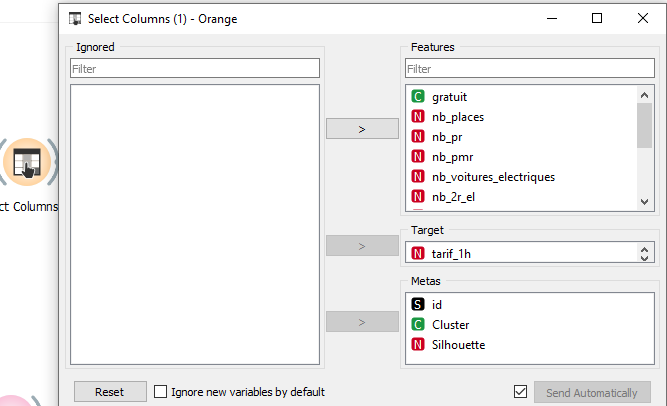
Une fois le fichier mis en qualité, nous devons sélectionner à l’aide du widget « Select Columns » uniquement les données qui vont nous intéresser pour faire nos analyses. Nos analyses vont se porter sur les tarifs à l’heure, nous allons éliminer toutes les données qui pourront induire en erreur nos analyses
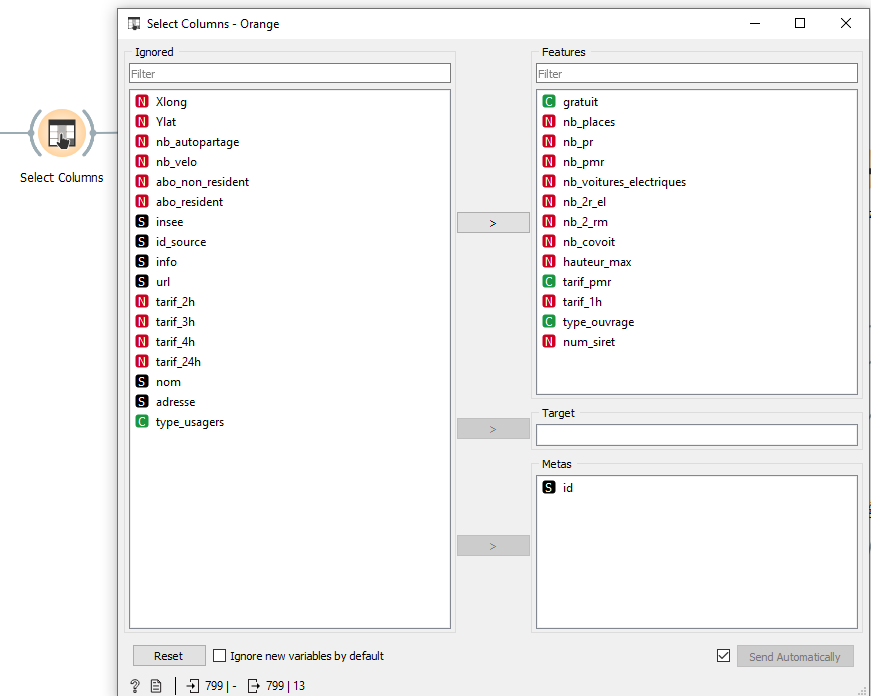
On peut donc voir que dans la partie gauche, nous avons tous les champs qui seront ignorés par les analyses et à droite les champs qui seront pris en compte.
Un fois cette étape terminée, nous avons presque notre jeu de données finales pour faire nos analyses, l’étape suivante et de dire sur quelles lignes les algorithmes vont se baser en ajoutant différentes contraintes sur les champs.
Dans notre cas, afin de ne pas fausser les résultats, nous avons décidé de se baser sur les lignes ayant tous les champs remplis.
Deuxième étape : Analyse des données
Nous avons enfin notre jeu de données final et nous allons pouvoir commencer à analyser les données afin de faire des prédictions.
La première étape va être de regrouper les parkings avec un algorithme de clustering qui est le k-Means, cet algorithme va créer des groupes de parkings ayant des caractéristiques similaires.
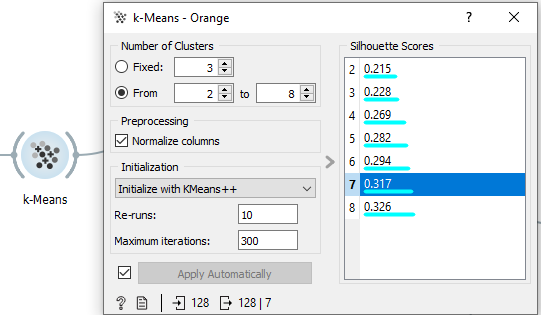
On peut voir ici qu’on peut choisir le nombre de clusters que notre algorithme va créer.
Chaque clusters est associé à un score de silhouette qui représente la qualité d’une partition d’un ensemble de données en classification automatique.
Nous allons donc choisir le score le plus élevé pour que nos analyses soient les meilleurs possibles.
Nous devons ensuite sélectionner la colonne sur laquelle nos analyses vont se porter, au vu de notre problématique nous allons donc cibler notre champ tarif_1h qui va nous permettre d’effectuer des prédictions sur ce champ.
Une fois notre cible choisie, nous allons regrouper nos données par intervalles grâce à un outil de discrétisation.
La discrétisation des données est une technique permettant de transformer un grand nombre de valeurs de données en valeurs plus petites, ce qui facilite l’interprétation et la gestion des données.
En d’autres termes, la discrétisation des données est une technique permettant de transformer les valeurs d’attributs de données continues en une collection finie d’intervalles avec peu de perte de données.
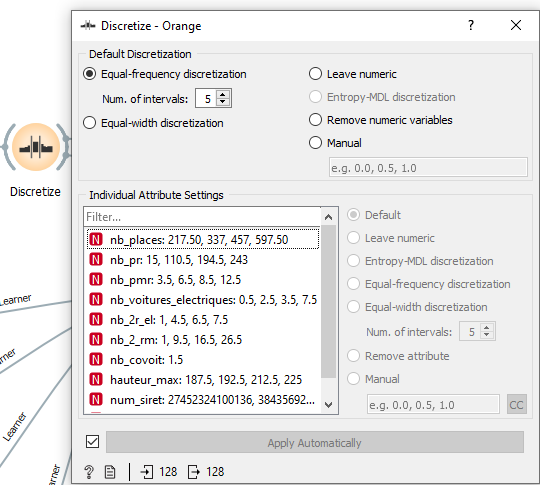
On peut voir ici les différents intervalles et attributs qui ont été discrétisés.
Passons à l’étape cruciale de notre schéma, qui est d’implémenter les différents modèles d’apprentissages, ce qu’on appelle également des learners.
Troisième étape : Les modèles d’apprentissages
Dans notre cas, nous avons utilisé 4 modèles d’apprentissages qui sont les suivants :
- Logistic Regression
- Neural Network
- kNN
- SVM
Ensuite, tous les résultats de nos modèles vont être remontés dans un autre widget qu’on appelle le Test and Score.
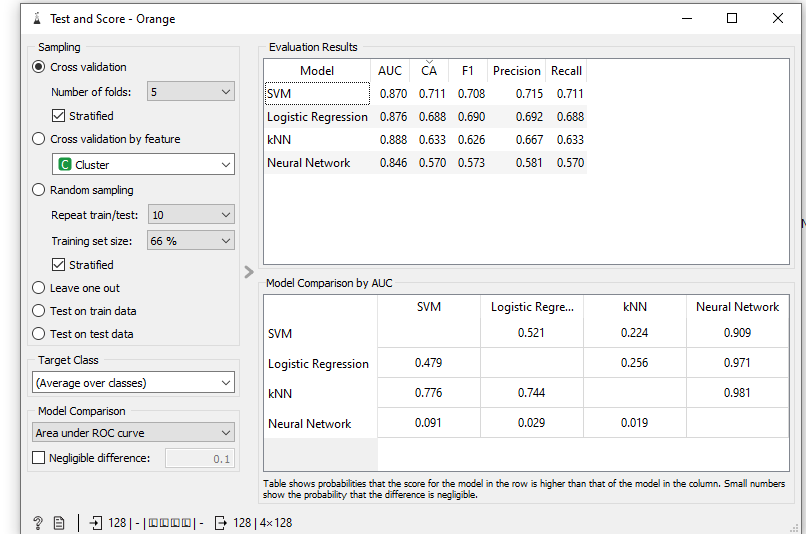
On peut remarquer donc les résultats dans la partie Evaluation Results où l’on peut voir les différents résultats par algorithme d’apprentissage.
La valeur qui va nous intéresser est le CA qui est la précision des algorithmes c’est-à-dire la proportion d’exemples correctement classés.
Dans notre cas, nous remarquons que c’est l’algorithme SVM qui est le plus performant avec une précision de 0,7.
Pour terminer, nous allons utiliser une matrice de confusion qui nous permettra de conclure et d’analyser les prédictions qui ont été faites.
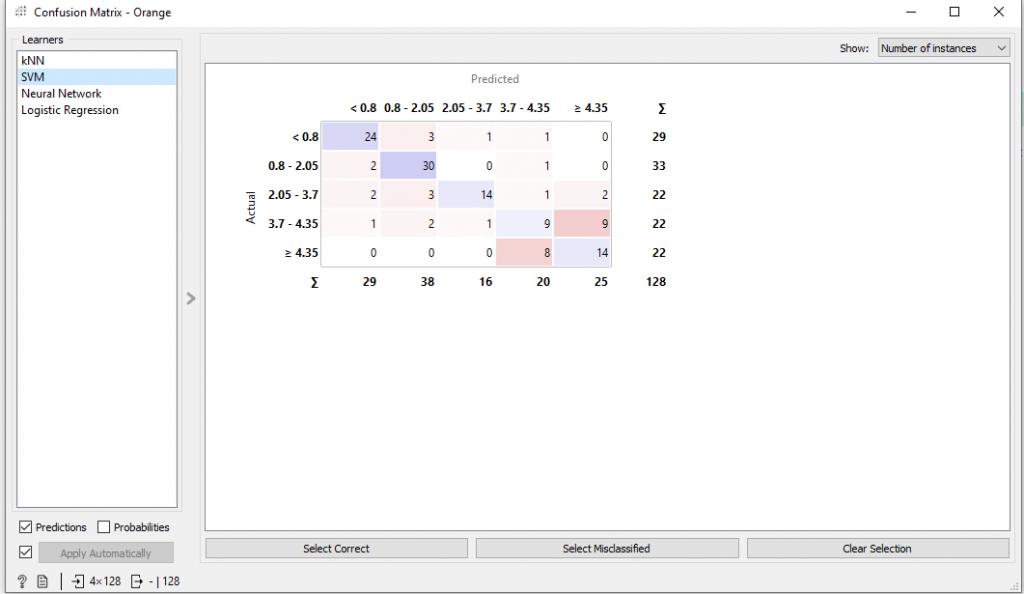
Dans cette matrice, nous avons donc à gauche les prix à l’heure réels et en haut les prix qui ont été prédits.
On peut remarquer que les cases bleues sur la diagonale sont le nombre de parkings qui ont été correctement prédits et les cases adjacentes sont les parkings avec des prix prédits différents du prix réel.
Par exemple, si on prend la première ligne on remarque que sur 29 parkings, 24 ont été prédits au prix réel affiché alors que 5 parkings ont été prédits avec un prix plus élevé.
Quatrième étape : Schéma final
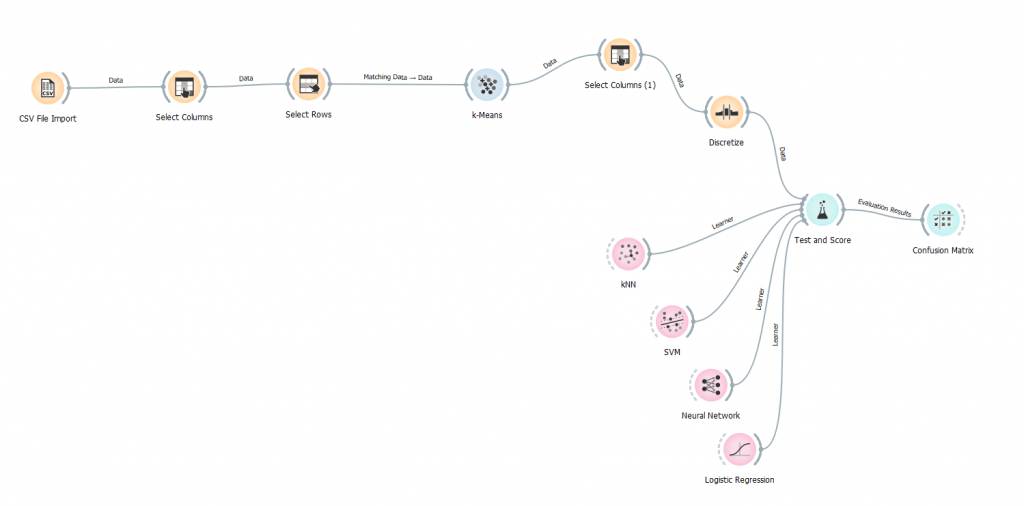
Pour conclure, les données analysées avec le logiciel Orange nous permettent de répondre à notre problématique car notre schéma et nos prédictions démontrent que certains parkings ont un prix trop faible ou trop élevé et que des ajustements pourraient être faits.
Vous avez aimé l'article ? Partagez-le autour de vous !
Vous aimerez aussi...
